On April 13, a tweet sparked outrage in the developer community.
Developer Can Vardar exclaimed:
Claude Code actually punishes you for turning off telemetry? Turn it off, and Anthropic cuts the cache from 1 hour to 5 minutes, privacy costs you a 12x performance penalty… Am I seeing this right?
 The retweets skyrocketed.
The retweets skyrocketed.
This is not a bug; it’s Anthropic’s invisible penalty for trading privacy for performance.
You might think turning off data collection is just about protecting yourself?
Wrong! Claude Code directly reverts your long context sessions. Pro users are left with only 2 prompts in 5 hours, while Max subscribers paying $200 a month burn through their quota in just 1.5 hours.
 It’s insane. Absolutely insane.
It’s insane. Absolutely insane.
Claude Continues to Decline!
From ‘Cache Evaporation’ to ‘12x Cost Explosion’
The facts are clear.
Developers discovered that by adding DISABLE_TELEMETRY=1 to the environment variables, the prompt cache TTL for Claude Code drops from 1 hour to a mere 5 minutes.
The data is here; the cache shrinks by 12 times.
On GitHub, Claude Code users shared real logs: with telemetry enabled, ephemeral_1h_input_tokens easily exceeded 30,000; once telemetry was disabled, it dropped to zero, all using 5m cache. The cache miss rate skyrocketed 12 times for the same code.
 In long context sessions, the cache is vital.
In long context sessions, the cache is vital.
When you make a request with prompt caching enabled, the system first checks whether the beginning of the prompt from your specified cache separation point has been stored in recent requests.
If it hits the cache, it calls the existing version, cutting time and costs by more than half.
If it misses? The entire prompt must be processed, and at the moment of generating a response, the beginning part is then cached.
Once the cache expires, the system must rebuild everything, with writing costs being 12.5 times that of reading. A 5-minute TTL means if you pause to think or make a coffee, returning means a full rebuild.
Even worse is yet to come.
Another developer, Sean Swanson, provided more solid evidence.
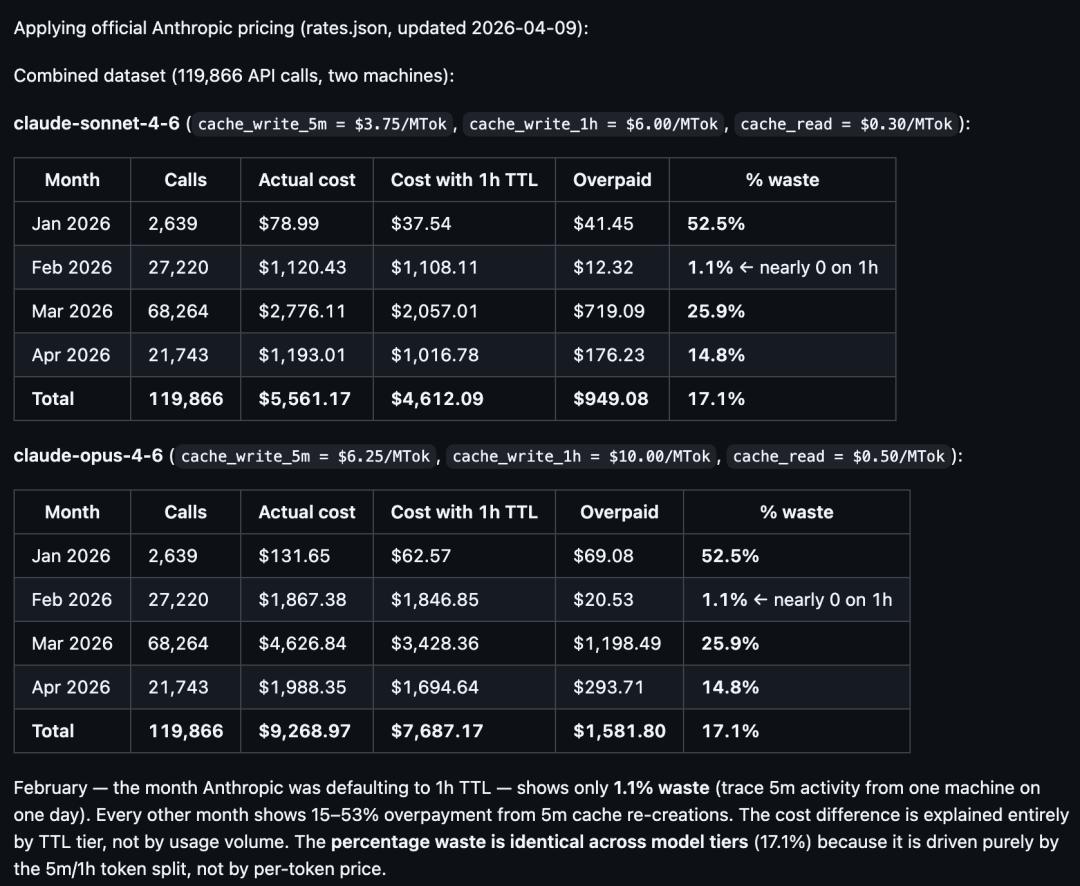
He analyzed 119,866 API call logs from January 11 to April 11, clearly showing the trajectory of cache policy changes:
In February, the 1-hour TTL was fully effective, with a waste rate of only 1.1%;
Around March 6, the system silently reverted to a 5-minute TTL, with the waste rate soaring to 25.9%.
What was the result? In the same session, the frequency of cache_create operations surged by 5-12 times.
 The cost of writing
The cost of writing cache_create is higher; 5m writes at 1.25 times base input, while 1h writes at 2 times, but frequent rebuilding causes total token consumption to skyrocket.
 Pro users are devastated: they used to easily max out their quotas in a day, now they hit the bottom in just 1.5 hours. The Max plan at $200/month burns through the quota with just fixing two bugs or drafting a plan.
Pro users are devastated: they used to easily max out their quotas in a day, now they hit the bottom in just 1.5 hours. The Max plan at $200/month burns through the quota with just fixing two bugs or drafting a plan.
 Enterprise teams are faring worse.
Enterprise teams are faring worse.
On Hacker News, someone mentioned that after the end of March, Claude’s performance visibly declined, with long sessions frequently stalling and token quotas dropping like a burst dam.
 On April 13, foreign tech media reported more directly: “Is Anthropic weakening Claude?”
On April 13, foreign tech media reported more directly: “Is Anthropic weakening Claude?”

Anthropic’s Defense
Not a Punishment, Just a Pipeline Break
Facing overwhelming criticism, Anthropic’s response came from two key figures.
Boris Cherny, the creator of Claude Code, personally replied.
He admitted that turning off telemetry does indeed cause the experiment gates to fail, reverting the cache to the default value of 5 minutes.
Breaking down the mechanism, it boils down to one statement:
The 1-hour cache is an “experimental” optimization pushed through client experiment gates. Only with telemetry enabled can the gates pull the latest strategy.
However, he emphasized that this is not a deliberate punishment but a coupling issue in architectural design.
Cherny also explained the design logic behind the cache strategy: Anthropic continuously tests different combinations of cache strategies in the background, aiming to optimize overall cache hit rates, token consumption, and latency performance.
 Once you turn off telemetry, the client directly reads the default value—5 minutes.
Once you turn off telemetry, the client directly reads the default value—5 minutes.
It’s not malicious; it’s a “technical side effect.”
In certain scenarios, a 5-minute cache is indeed more economical—like subagent calls, which are typically one-off requests and rarely read from the cache again, making a 1-hour TTL wasteful.
However, he also acknowledged: “With many skills, multiple agents, or background automation tasks running simultaneously, token consumption is indeed high, especially when using many plugins.”
Surprisingly, the number of affected users is quite large, and Anthropic is working on improvements:
(a) Optimizing UX to make users more aware of these situations;
(b) More intelligently truncating, pruning, and scheduling non-primary tasks to avoid unexpected token consumption.
 Another Anthropic engineer, Jarred Sumner, creator of the Bun runtime, responded to the March TTL rollback issue.
Another Anthropic engineer, Jarred Sumner, creator of the Bun runtime, responded to the March TTL rollback issue.
He believes the 5-minute TTL is “cheaper overall rather than more expensive,” because “a significant portion of Claude Code requests are one-off calls, and the cached context is only used once and not accessed again.”
 Honestly, this explanation makes sense on a technical level, but users are not buying it.
Honestly, this explanation makes sense on a technical level, but users are not buying it.
The problem is that Swanson’s data directly contradicts this: in February, the waste rate under the 1-hour TTL was only 1.1%, and if most requests were indeed one-off, there should have been a lot of writing waste in February.
A Real Industry Issue
AI Token Pricing is a Black Box
Looking at the bigger picture, this is not just an issue for Anthropic.
Currently, billing for AI coding tools based on usage is purely a test of trust.
Developers cannot see the fluctuations in billing, cannot audit token usage for each request, cannot verify cache status, cannot confirm which pricing tier is applied, and cannot check if peak multipliers are in effect.
 Comparing this to other paid infrastructure used by developers:
Comparing this to other paid infrastructure used by developers:
- AWS EC2: billed by the second, complete instance visibility, CloudWatch metrics, billing alerts, cost analysis tools
- Stripe: billed per transaction, each fee has logs and is auditable, real-time dashboards
- Vercel: billed per invocation, function-level metrics, spending limits, automatic alerts
- Claude Code: billed by token, no detailed usage for single requests, no visibility into cache hits, no spending alerts, no real-time cost tracking
This information asymmetry is shocking. All other developer tools in this price range allow users to understand their costs in detail. In contrast, AI programming assistants provide users with only a quota progress bar and a prayer.
This asymmetry benefits service providers under normal circumstances, but when issues arise, it can lead to devastating consequences for users.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.