Claude’s Decline
Recently, many users have expressed a troubling feeling about Claude Opus: while the model doesn’t make obvious mistakes, it no longer seems as “smart” as before. Responses are quicker, reasoning is shorter, and at times it appears to skip steps that should be completed thoroughly, becoming somewhat perfunctory.
If this were just an isolated incident, users might suspect it was their own issue. However, as similar feedback began to accumulate, it became clear this was more than just a feeling. Some online videos humorously compare the current Opus to a fierce lion that has been declawed, revealing it to be just a dog.
A more direct phrase has started circulating: Opus has been nerfed! Is this true? If so, why would it be nerfed?
Decline in Reasoning Depth by 67%
Initially, only a few users complained that Claude Opus had become “lazy” or “less intelligent.” They noted occasional basic errors that it previously would not have made or fewer reasoning steps in complex tasks.
In a sense, interacting with the model is similar to dealing with a human colleague; if a previously reliable partner suddenly changes, it can be disheartening. Most people’s first reaction is self-doubt: Is my prompt not good enough? Is the task unsuitable? Surely this is just a coincidence?
However, soon similar feedback began to appear densely in the Claude community on Reddit, with highly consistent descriptions:
- Some said it no longer reads code carefully.
- Others noted it gives answers faster but often misses key steps.
- Many found that it tends to “finish early” on long tasks, as if it assumes the job is done.
When different users across various scenarios start reporting the same types of issues, it seems less like a mere feeling and more like a behavioral pattern change. In other words, it’s not that users are wrong; the model is genuinely changing.
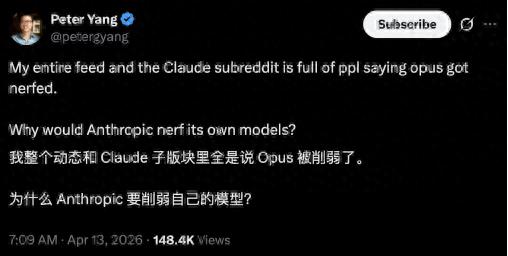
What escalated the discussion was this number: some users compared historical interaction logs during their use of Claude Code and found that the reasoning process in complex tasks had significantly shortened, with a 67% decline in reasoning depth since the February update.

The author candidly notes that the 67% figure is based on a correlation between signature length and the length of thought content, rather than direct measurement. They also mentioned that logs from January were deleted, making baseline comparisons less accurate.
In contrast, more convincing are the behavioral changes reported. For example, the ratio of read:edit (reading code vs. modifying code) dropped from 6.6 to 2.0; since March 8, there have been 173 violations caught by the stop hook, compared to zero before.
However, the precision of these numbers is not as important as the fact that they quantify a previously vague sensation into a trend that can be discussed. Thus, a new term began to circulate in the community: “AI shrinkflation.”
Shrinkflation is an economic term referring to a reduction in the size or quantity of a product while the price remains the same. In this context, it means that the actual capabilities delivered to users have decreased, yet the model still carries the same name.
The Reasons Behind the Decline
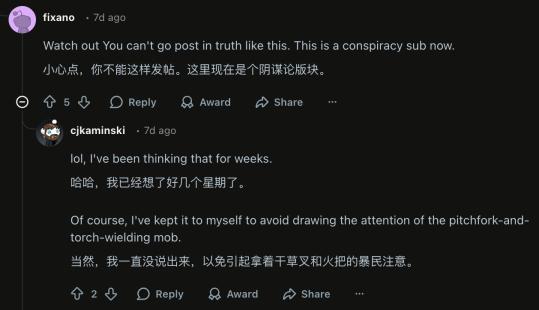
In contrast to the community’s heated reactions, Anthropic has not directly acknowledged that the “model has weakened.” Boris, the head of Claude Code development, explained that these changes stem from adjustments at the system level, including changes in tool invocation methods, reasoning strategies, and resource allocation mechanisms, rather than a decrease in the model’s inherent capabilities.
He provided an example: in Claude Code, some issues are believed to originate from the toolchain and system prompts, not the model itself. Meanwhile, under high load, the system needs to manage computing power, tokens, and requests, which can also affect user experience.
In the latest version, Anthropic introduced a mechanism called “adaptive thinking,” where the model dynamically decides how much reasoning to use based on task complexity. In other words, the model isn’t worse; it simply decides for itself how much computing power to employ.

From an engineering perspective, this is a reasonable optimization: less thinking for simple tasks, more for complex ones, to enhance overall efficiency. However, the problem is that efficiency optimization and capability reduction feel indistinguishable to the user experience.
When a model starts reading less context, providing answers faster, and finishing tasks more frequently, users perceive this not as optimization but as carelessness. Furthermore, this adaptive reasoning mechanism can indeed create discomfort from a subjective standpoint.
Returning to the interpersonal analogy: why is it that something that started well suddenly feels unimportant?
This discomfort is amplified by another change: Claude Mythos Preview, which has not yet been released, is already receiving significant attention. Anthropic has referred to it as a “generational leap in capability,” showing far superior performance in coding and safety tasks. Hence, it is being restrictively provided to a few institutions to bolster “the world’s most critical software systems.”
When a “stronger new model” appears alongside an “old model” that feels diminished, a speculation that has been increasingly discussed in the community begins to take shape: by nerfing the old model before launching the new one, it creates a perception of a significant upgrade.
While there is no direct evidence for this logic, it is gaining traction among users.
Models No Longer Stable
In reality, similar situations are not unfamiliar in the AI field. As early as 2023, research compared GPT-4’s performance over time, revealing significant changes in reasoning methods and output behavior within a few months. These changes were later explained as the result of multiple factors, including adjustments in reasoning strategies, tightening of safety policies, and optimizations for cost and response speed.

Setting conspiracy theories aside, if there is indeed a certain degree of resource bias, it is quite normal in the AI industry: whether OpenAI or Google, almost all companies prioritize optimizing the latest generation of models while gradually marginalizing older ones. Computing power is both a cost and a productivity factor. When the upper limits of a new model’s capabilities are higher and its potential value greater, allocating more resources to it is a rational choice.
In this process, the state of the old model will naturally change: it may be “downgraded,” its reasoning depth compressed, and resource allocation readjusted. These can all be understood as engineering trade-offs.
However, understanding this does not make it easy to accept that the new model is not available to the public while the old model undergoes such changes without warning.
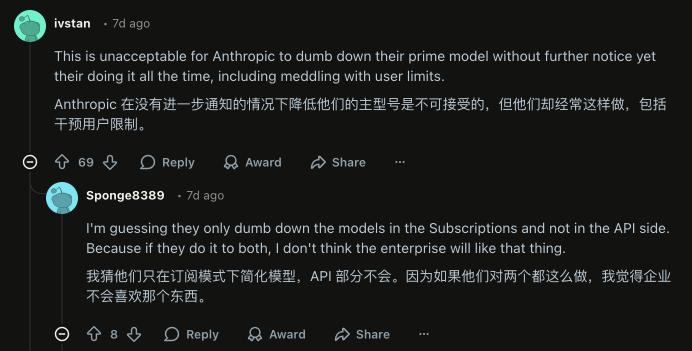
From the user’s perspective, the most frustrating aspect is not the model’s “decline” but its “instability.” When a model transitions from being a stable tool to a system that constantly changes, making its own “better adjustments” without notifications, version notes, or boundaries, it becomes problematic.
As a user, you don’t know when it changed, what specifically changed, or whether these changes will affect your ongoing tasks. You can only feel that it has changed, and it is no longer as useful as before.
At this point, a new model appears before you, seemingly more stable and reliable, perhaps easier to use. Thus, the choice becomes nuanced: it seems you are no longer actively choosing the new model; rather, the changes in the old model push you toward the newer one.
Even if you know that the new model may someday become the next old model, potentially undergoing uncomfortable “optimizations” without warning, the difference is already apparent at that moment.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.