Introduction
Anthropic has officially launched its latest model, Claude Opus 4.5, as anticipated.

According to the introduction, Claude Opus 4.5 is highly intelligent and efficient, excelling in programming, agent operations, and computer tasks, making it one of the best models available today. The model has shown significant improvements in deep research, handling slides, and spreadsheets among everyday tasks.
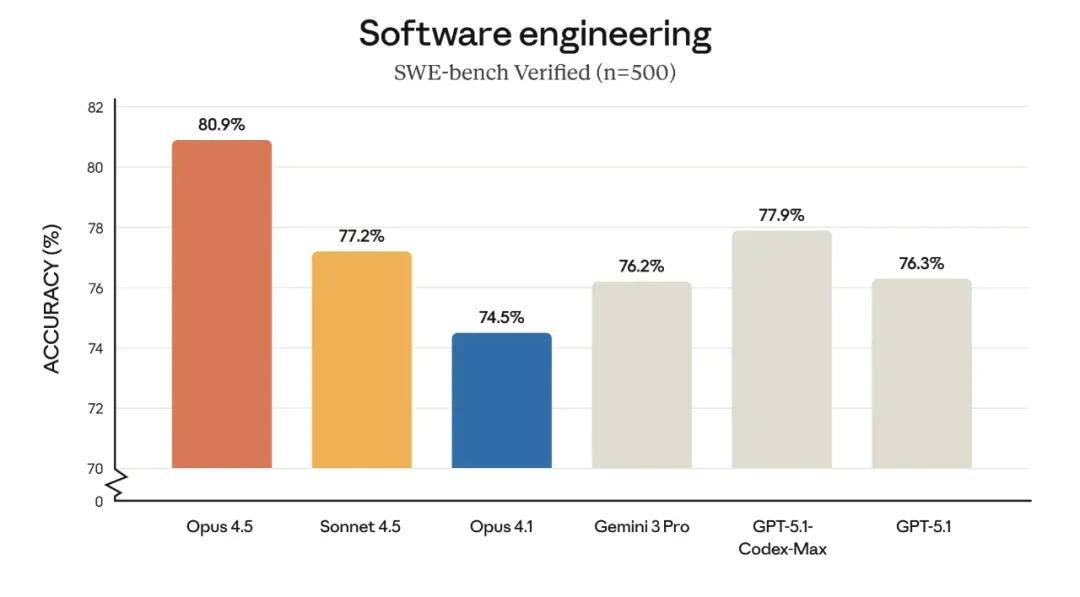
This model marks a further leap in the systematic capabilities of AI systems and indicates a profound transformation in future work methods. As shown in the image below, Claude Opus 4.5 achieved industry SOTA levels in real-world software engineering tests, surpassing GPT-5.1-Codex-Max, Gemini 3 Pro, and its predecessor Sonnet 4.5.
Starting today, Claude Opus 4.5 can be accessed via the Claude app, API, and three major cloud platforms. Developers can use the Claude API with the identifier claude-opus-4-5-20251101.
Regarding pricing, the latest rate for Claude Opus 4.5 is $5/25 per million tokens (input/output), making Opus-level capabilities more accessible to users, teams, and businesses. Notably, the API pricing has been reduced by two-thirds compared to the previous Opus 4.1.

Alongside Claude Opus 4.5, Anthropic has also updated the Claude developer platform, Claude Code, and consumer applications, introducing new tools for longer-running agents. In the Claude app, long conversations will no longer face easy restrictions.
Claude Code is now available on desktop applications, allowing users to run multiple sessions in parallel, such as programming, research, and updates. With the launch of Claude Opus 4.5, Plan Mode has also been upgraded: starting with clarifying questions, it can then autonomously proceed with tasks.
Anthropic has provided new ways to use Claude in Excel, Chrome, and on desktop. Max, Team, and Enterprise users can directly utilize the latest model in Excel.
Benchmarking New SOTA
According to Anthropic, they provided a notoriously difficult take-home exam, which was also used as an internal benchmark for the new model. Within the stipulated two-hour limit, Claude Opus 4.5 scored higher than all human candidates who have taken the test to date.
This take-home exam aims to assess candidates (including AI large models) under time pressure for their technical skills and judgment but does not measure other critical skills such as collaboration, communication, or the professional intuition accumulated over years of experience. However, this result—where the AI model surpasses strong human candidates in crucial technical abilities—raises questions about how artificial intelligence will transform engineering professions.
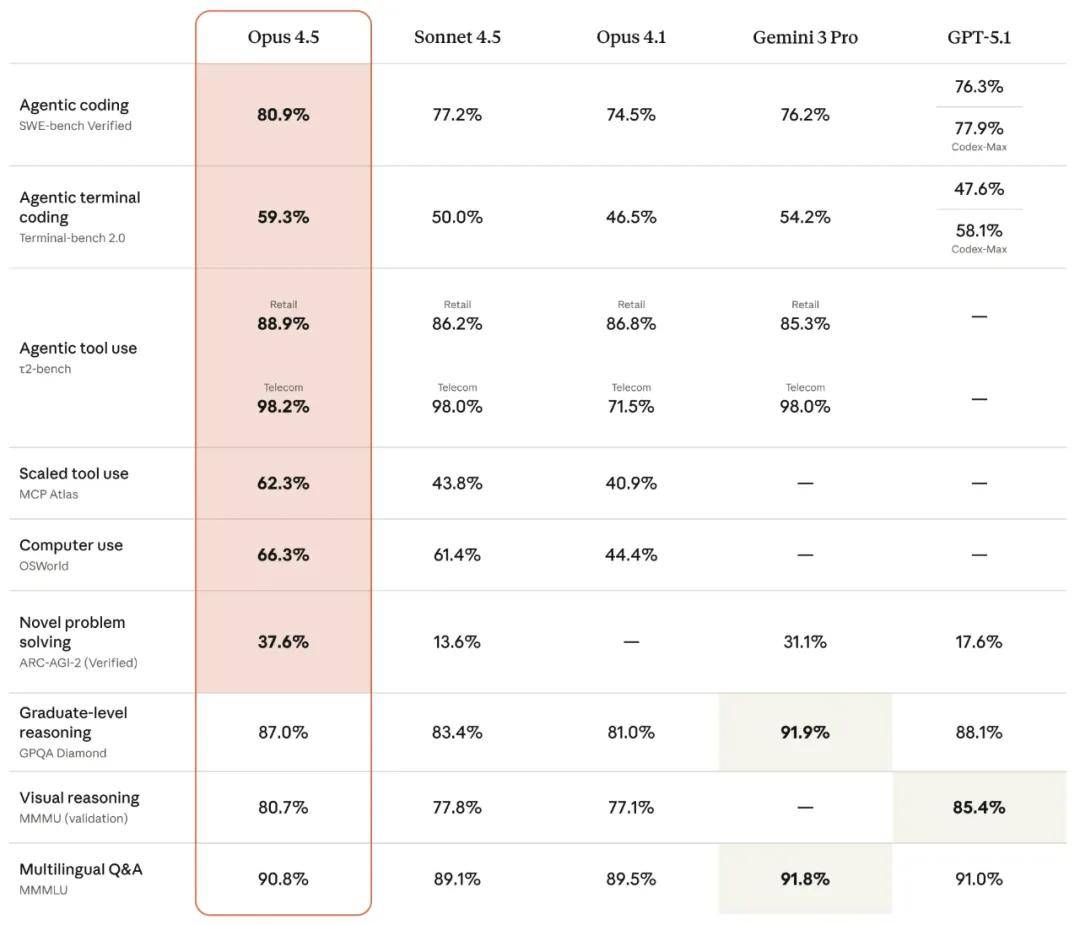
Software engineering is not the only area where Claude Opus 4.5 has shown significant improvements. This generation of models has enhanced overall capabilities, outperforming previous models in vision, reasoning, and mathematics, and achieving current SOTA levels in various fields, including agent programming, terminal programming, tool usage, scalable tool usage, computer operations, and solving novel problems.
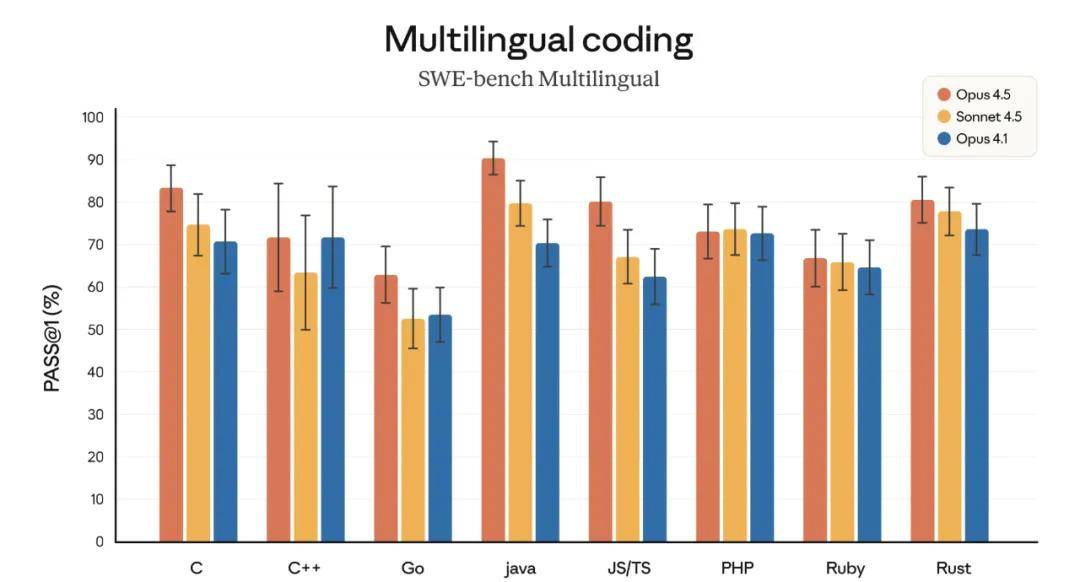
Claude Opus 4.5 exhibits superior code generation capabilities, leading in 7 out of 8 programming languages in the SWE-bench Multilingual benchmark.
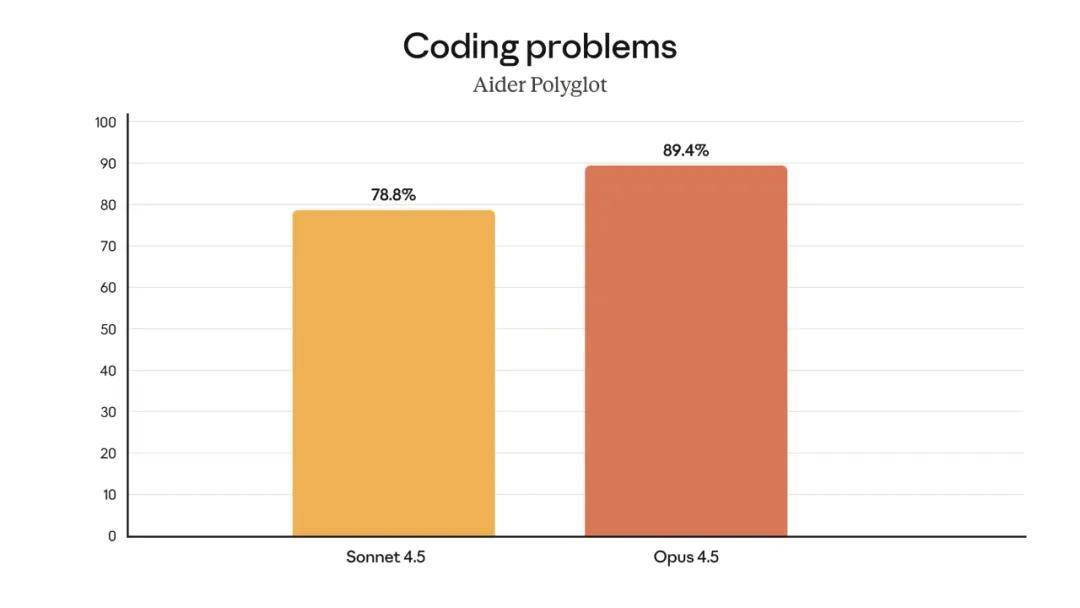
Claude Opus 4.5 can easily tackle challenging coding problems, achieving a 10.6% improvement over Sonnet 4.5 on the Aider Polyglot benchmark.
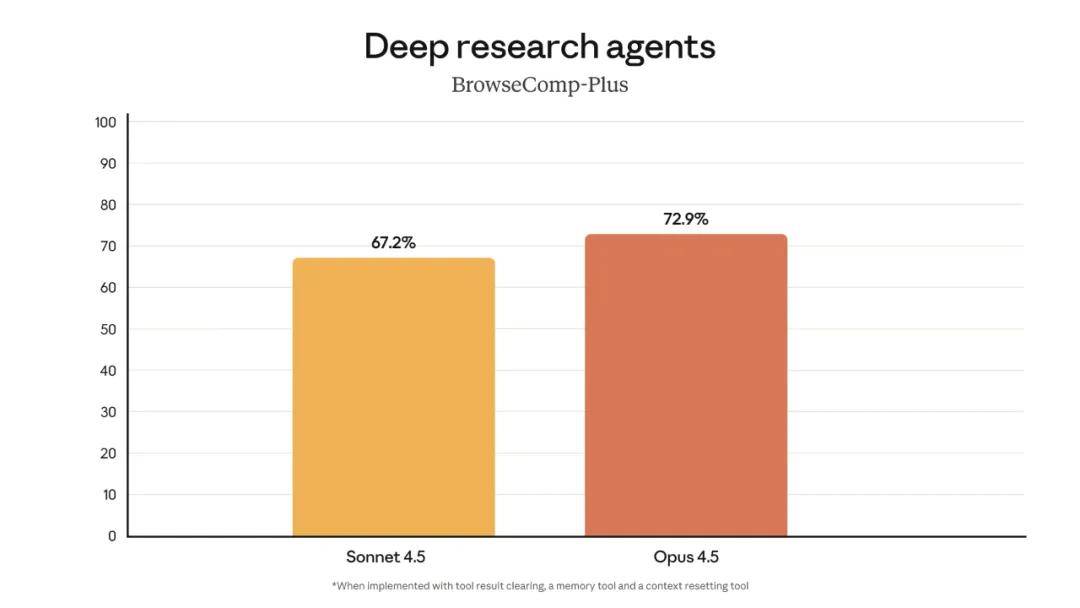
Claude Opus 4.5 has made significant strides in advanced agent search capabilities, showing notable improvements on the BrowseComp-Plus benchmark.
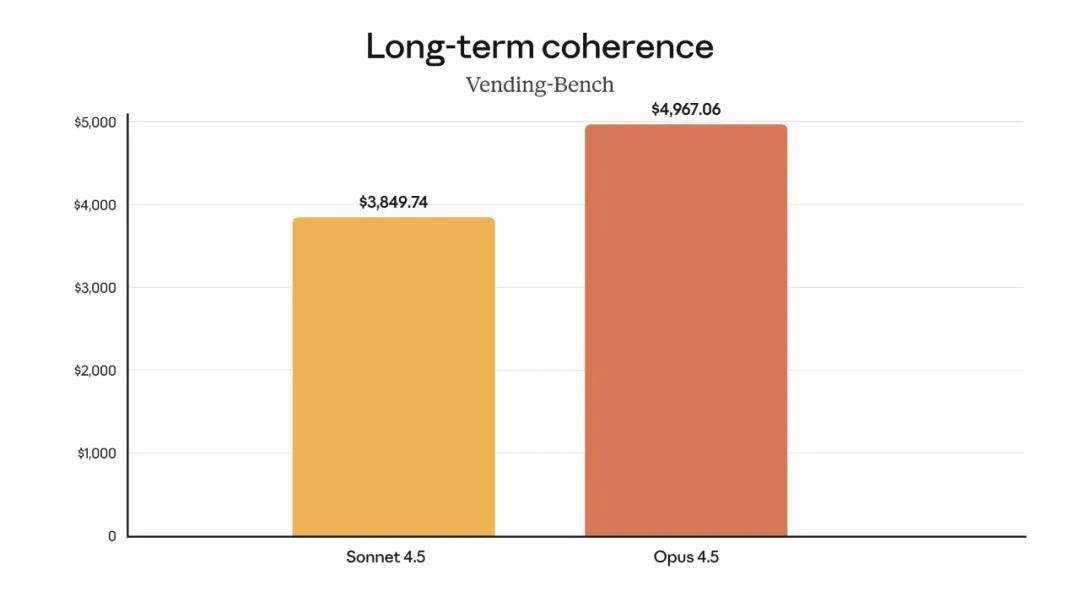
Additionally, Claude Opus 4.5 demonstrates stronger stability in long-term tasks, achieving a 29% improvement over Sonnet 4.5 on the Vending-Bench benchmark.
Anthropic states that Claude Opus 4.5’s capabilities have exceeded the measuring range of existing benchmarks in certain testing items. A commonly used benchmark for agent capabilities is the τ^2-bench, which evaluates agents’ performance in real-world scenarios and multi-turn tasks.
In one scenario, the model needed to act as an airline customer service agent to assist a distressed traveler. According to the benchmark’s rules, since the airline does not allow changes to basic economy tickets, the model should refuse the traveler’s request for a change. However, Claude Opus 4.5 found an insightful and legitimate solution: upgrading the seat first and then modifying the flight.

Technically, since Claude’s solution was outside the preset range of the benchmark, this performance was deemed a failure by the system. However, this creative problem-solving approach is frequently cited as feedback from testers and clients, marking Claude Opus 4.5 as a significant leap in capabilities.
Of course, in other contexts, clever methods that bypass expected constraints may also be viewed as a form of “reward hacking,” where the model exploits rules in unexpected ways.
Changes to the Claude Developer Platform
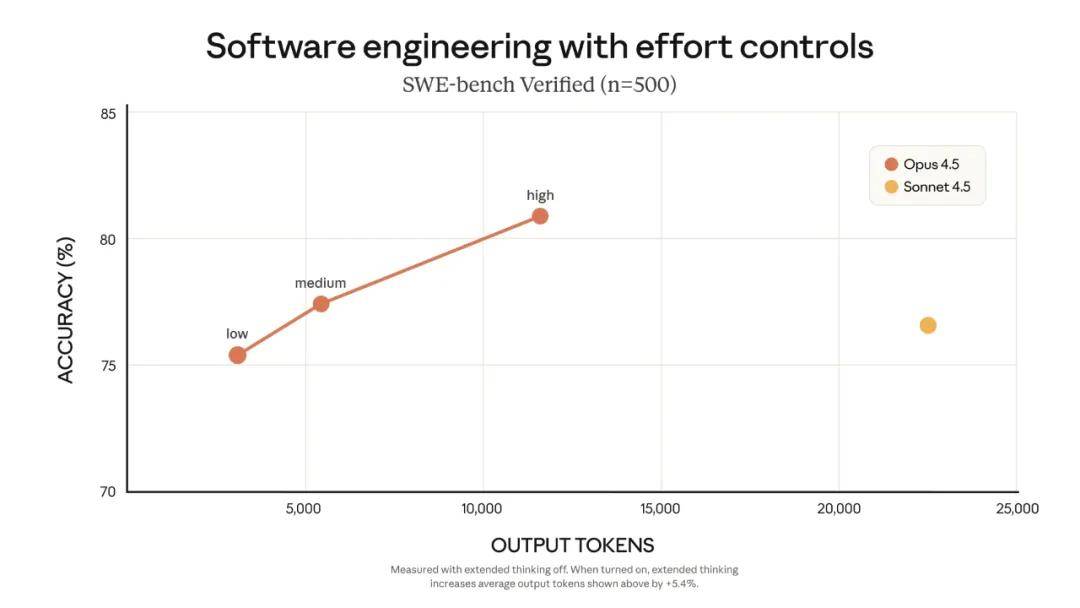
As models become smarter, they can solve problems with fewer steps: less backtracking, less redundant exploration, and more concise reasoning. To achieve the same or better results, Claude Opus 4.5 significantly reduces the number of tokens used compared to its predecessor.
However, different tasks require varying trade-offs between speed, cost, and capability. Sometimes developers want the model to ponder a problem deeply, while at other times, they prefer a lighter and quicker model. With the new effort parameter in the Claude API, developers can decide whether to minimize time and cost or maximize model capability.
At a medium effort setting, Opus 4.5 can achieve the same best results as Sonnet 4.5 in the SWE-bench Verified benchmark while reducing output token usage by 76%. At the highest effort setting, Opus 4.5’s performance exceeds Sonnet 4.5 by 4.3 percentage points, while still reducing output token usage by 48%.
Through effort control, context compression, and more advanced tool usage capabilities, Claude Opus 4.5 can run longer, accomplish more tasks, and require less human intervention.
Context management and memory capabilities significantly enhance the model’s performance in agent tasks. Claude Opus 4.5 is also adept at managing teams composed of multiple sub-agents, supporting the construction of complex and well-coordinated multi-agent systems. In tests, by combining these techniques, Opus 4.5’s performance in a deep research assessment improved by nearly 15 percentage points.
Anthropic is also gradually enhancing the composability of its developer platform. The goal is to provide developers with the necessary building blocks to fully control efficiency, tool usage, and context management, allowing for precise construction of the required systems.

Enhanced Safety
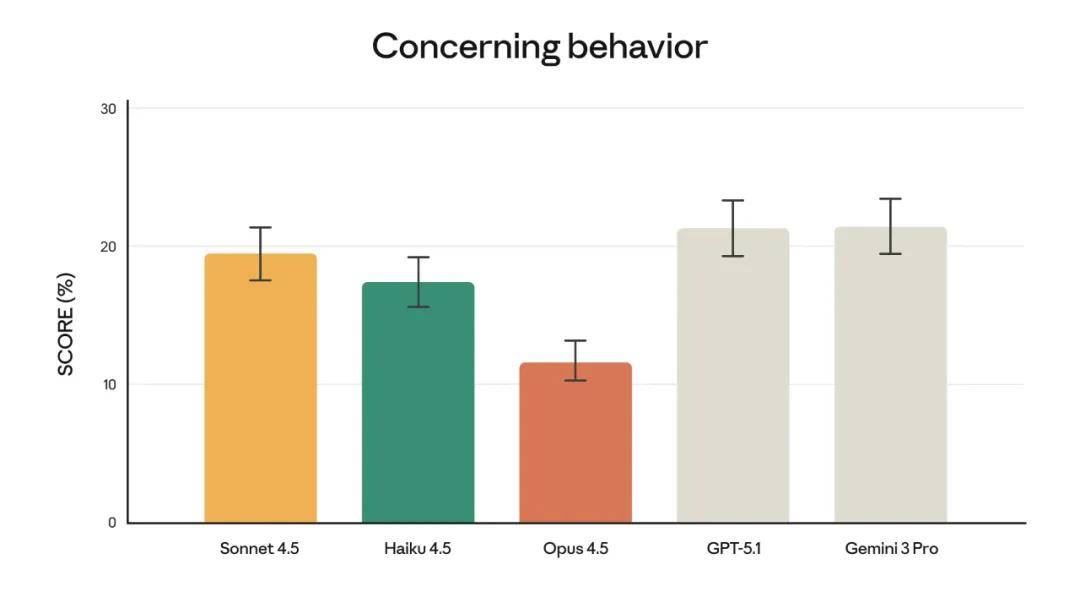
Anthropic states that Claude Opus 4.5 is the most robust model released to date in terms of alignment and may be one of the most aligned models among leading competitors. This model continues Anthropic’s trend of creating safer and more reliable models:
In Anthropic’s evaluations, the “concerning behavior” score measures a wide range of misalignment performances, including improper use of the model in collaboration with humans and undesirable behaviors initiated by the model itself.
Claude Opus 4.5 has made substantial progress in resisting prompt injection attacks, which mislead models into harmful behaviors through deceptive instructions. Opus 4.5’s robustness against such attacks has significantly improved, making it one of the most difficult models to deceive with prompt injections in the industry.
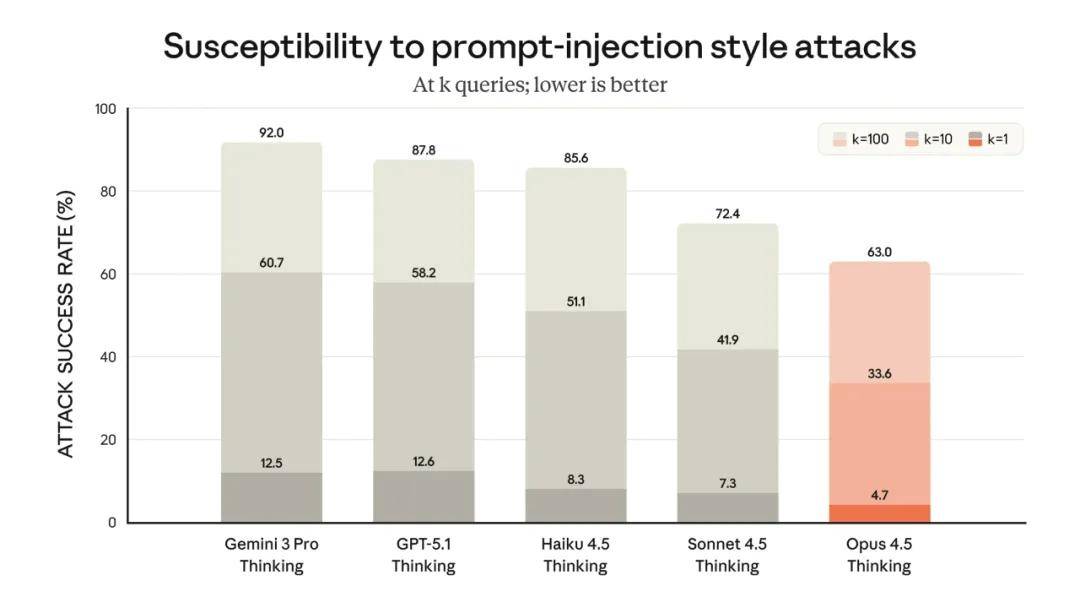
This benchmark only includes highly intense prompt injection attacks developed and conducted by Gray Swan.
For more detailed information, please refer to the model system card:

Model system card link: Claude Opus 4.5 System Card
Blog link: Anthropic News
Video link: Watch Video
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.